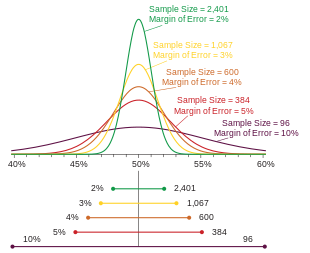
Densités de probabilité de sondages de différentes tailles, chacune codée par couleur selon son
intervalle de confiance à 95 % (ci-dessous), la marge d'erreur (à gauche) et la taille de l'échantillon (à droite). Chaque intervalle reflète la plage dans laquelle on peut avoir une confiance de 95 % que le
vrai pourcentage peut être trouvé, étant donné un pourcentage rapporté de 50 %. La
marge d'erreur est la moitié de l'intervalle de confiance (également, le
rayon de l'intervalle). Plus l'échantillon est grand, plus la marge d'erreur est petite. De plus, plus le pourcentage rapporté est éloigné de 50 %, plus la marge d'erreur est faible.
La marge d'erreur est une statistique exprimant la quantité d' erreur d'échantillonnage aléatoire dans les résultats d'une enquête . Plus la marge d'erreur est grande, moins on devrait avoir confiance qu'un résultat de sondage refléterait le résultat d'un sondage auprès de l'ensemble de la population . La marge d'erreur sera positive chaque fois qu'une population est incomplètement échantillonnée et que la mesure des résultats a une variance positive , c'est-à-dire que la mesure varie .
Le terme marge d'erreur est souvent utilisé dans des contextes autres que les enquêtes pour indiquer une erreur d'observation dans la déclaration des quantités mesurées. Il est également utilisé dans le discours familier pour désigner la quantité d'espace ou la quantité de flexibilité dont on peut disposer pour atteindre un objectif. Par exemple, il est souvent utilisé dans le sport par les commentateurs pour décrire la précision requise pour atteindre un objectif, des points ou un résultat. Une quille de bowling utilisée aux États-Unis mesure 4,75 pouces de large et la balle mesure 8,5 pouces de large. restant sur la voie).
Concept
Considérez un simple sondage oui/non comme un échantillon de répondants tirés d'une population déclarant le pourcentage de réponses oui . Nous aimerions savoir à quel point on se rapproche du vrai résultat d'une enquête sur l'ensemble de la population , sans avoir à en faire une. Si, par hypothèse, nous devions mener un sondage sur des échantillons ultérieurs de répondants (nouvellement tirés de ), nous nous attendrions à ce que ces résultats ultérieurs soient normalement distribués autour de . La marge d'erreur décrit la distance à l'intérieur de laquelle un pourcentage spécifié de ces résultats devrait varier de .







Selon la règle 68-95-99,7 , nous nous attendrions à ce que 95 % des résultats se situent à environ deux écarts types ( ) de chaque côté de la vraie moyenne . Cet intervalle est appelé intervalle de confiance , et le rayon (la moitié de l'intervalle) est appelé marge d'erreur , correspondant à un niveau de confiance de 95% .

Généralement, à un niveau de confiance , un échantillon de la taille d'une population ayant un écart type attendu a une marge d'erreur



où désigne le quantile (également, généralement, un z-score ), et est l' erreur standard .


Écart-type et erreur-type
Nous nous attendrions à ce que les valeurs normalement distribuées aient un écart type qui varie en quelque sorte avec . Plus la marge est petite , plus la marge est large. C'est ce qu'on appelle l' erreur standard .

Pour le seul résultat de notre enquête, nous supposons que , et que tous les résultats ultérieurs ensemble auraient une variance .



Notez que correspond à la variance d'une distribution de Bernoulli .

Marge d'erreur maximale à différents niveaux de confiance
Pour un niveau de confiance , il existe un intervalle de confiance correspondant à la moyenne , c'est-à-dire l'intervalle dans lequel les valeurs de devraient tomber avec la probabilité . Les valeurs précises de sont données par la fonction quantile de la distribution normale (dont la règle 68-95-99,7 se rapproche).

![{\displaystyle [\mu -z_{\gamma }\sigma ,\mu +z_{\gamma }\sigma ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94)
Notez que n'est pas défini pour , c'est-à-dire qu'il n'est pas défini, tout comme .



|
|
|
|
|
|
| 0,68
|
0,994 457 883 210
|
0,999
|
3.290 526 731 492
|
| 0,90
|
1.644 853 626 951
|
0,9999
|
3.890 591 886 413
|
| 0,95
|
1.959963984540
|
0.99999
|
4.417 173 413 469
|
| 0,98
|
2.326 347 874 041
|
0.999999
|
4.891 638 475 699
|
| 0.99
|
2.575 829 303 549
|
0.9999999
|
5.326 723 886 384
|
| 0,995
|
2.807 033 768 344
|
0.99999999
|
5.730 728 868 236
|
| 0,997
|
2.967 737 925 342
|
0.999999999
|
6.109 410 204 869
|
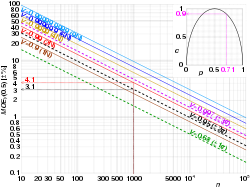
Graphiques log-log en fonction de la taille de l'échantillon
n et du niveau de confiance γ . Les flèches montrent que la marge d'erreur maximale pour un échantillon de 1 000 est de ±3,1 % à un niveau de confiance de 95 % et de ±4,1 % à 99 %. La parabole en médaillon illustre la relation entre à et à . Dans l'exemple, MOE 95 (0,71) 0,9 × ±3,1 % ≈ ±2,8 %.





Depuis à , nous pouvons arbitrairement définir , calculer , , et obtenir la marge d'erreur maximale pour un niveau de confiance et une taille d'échantillon donnés , avant même d'avoir des résultats réels. Avec






Aussi, utilement, pour tout rapport 

Marges d'erreur spécifiques
Si un sondage a plusieurs résultats en pourcentage (par exemple, un sondage mesurant une seule préférence à choix multiples), le résultat le plus proche de 50 % aura la marge d'erreur la plus élevée. En règle générale, c'est ce nombre qui est signalé comme marge d'erreur pour l'ensemble du sondage. Imaginez les rapports de sondage comme

-
 (comme dans la figure ci-dessus)
(comme dans la figure ci-dessus)


Lorsqu'un pourcentage donné approche les extrêmes de 0 % ou 100 %, sa marge d'erreur approche ± 0 %.
Comparer les pourcentages
Imaginez sondage à choix multiples rapports que . Comme décrit ci-dessus, la marge d'erreur signalée pour le sondage serait généralement de , car elle est la plus proche de 50 %. La notion populaire d' égalité statistique ou de dead heat statistique, cependant, ne se préoccupe pas de l'exactitude des résultats individuels, mais de celle du classement des résultats. Lequel est en premier ?



Si, hypothétiquement, nous devions mener un sondage sur des échantillons ultérieurs de répondants (nouvellement tirés de ) et rapporter le résultat , nous pourrions utiliser l' erreur type de différence pour comprendre comment devrait tomber environ . Pour cela, nous devons appliquer la somme des variances pour obtenir une nouvelle variance, ,





où est la covariance de et .



Ainsi (après simplification),



Notez que cela suppose que est proche de constant, c'est-à-dire que les répondants choisissant A ou B ne choisiraient presque jamais C (ce qui rend et proche de parfaitement corrélé négativement ). Avec trois choix ou plus en conflit plus étroit, le choix d'une formule correcte pour devient plus compliqué.

Effet de la taille de la population finie
Les formules ci-dessus pour la marge d'erreur supposent qu'il existe une population infiniment grande et ne dépendent donc pas de la taille de la population , mais uniquement de la taille de l'échantillon . Selon la théorie de l'échantillonnage , cette hypothèse est raisonnable lorsque la fraction d'échantillonnage est faible. La marge d'erreur pour une méthode d'échantillonnage particulière est essentiellement la même, que la population d'intérêt soit de la taille d'une école, d'une ville, d'un état ou d'un pays, tant que la fraction d' échantillonnage est petite.
Dans les cas où la fraction d'échantillonnage est plus importante (en pratique, supérieure à 5%), les analystes peuvent ajuster la marge d'erreur en utilisant une correction de population finie pour tenir compte de la précision supplémentaire obtenue en échantillonnant un pourcentage beaucoup plus important de la population. Le FPC peut être calculé à l'aide de la formule

...et donc si le sondage était mené sur plus de 24 % d'un électorat de 300 000 votants


Intuitivement, pour une taille appropriée ,


Dans le premier cas, est si petit qu'il ne nécessite aucune correction. Dans ce dernier cas, le sondage devient effectivement un recensement et l'erreur d'échantillonnage devient théorique.
Voir également
Remarques
Les références
- Sudman, Seymour et Bradburn, Norman (1982). Poser des questions : un guide pratique pour la conception de questionnaires . San Francisco : Josey Bass. ISBN 0-87589-546-8
-
Wonnacott, TH et RJ Wonnacott (1990). Statistiques d'introduction (5e éd.). Wiley. ISBN 0-471-61518-8.
Liens externes



